IT/모바일
제공 : 한빛 네트워크
저자 : Ben Lorica
역자 : 하혜진
원문 : Spark 0.6 improves performance and accessibility
Spark의 개발팀은 Spark를 쓰는 유저들이 늘어날 수 있는 기능을 제공하는데 노력하고 있다.
 저번 포스트에서 왜 내가 Spark를 수용했고 쓰는지 몇 가지 이유를 나열했었다. 나는 특히 Spark가 왜 반복되는 계산이나 상호연관된 쿼리같은 많이 분산된 빅데이터 분석업무에 Hadoop을 능가할만큼 잘 맞는지 설명했었다. 버전 0.6에서 Spark는 더 빨라지고 더 쓰기 쉬워진다(0). 릴리즈노트는 모든 세세한 변경을 포함하지만, 아래 highlights(1)에서 확인할 수 있듯이 버전 0.6은 상당히 중요한 버전이다. 또 다른 좋은 신호는 개발자들의 3분의 1이 버클리의 핵심팀에서 온다는 것과 참여자의 증가이다.
저번 포스트에서 왜 내가 Spark를 수용했고 쓰는지 몇 가지 이유를 나열했었다. 나는 특히 Spark가 왜 반복되는 계산이나 상호연관된 쿼리같은 많이 분산된 빅데이터 분석업무에 Hadoop을 능가할만큼 잘 맞는지 설명했었다. 버전 0.6에서 Spark는 더 빨라지고 더 쓰기 쉬워진다(0). 릴리즈노트는 모든 세세한 변경을 포함하지만, 아래 highlights(1)에서 확인할 수 있듯이 버전 0.6은 상당히 중요한 버전이다. 또 다른 좋은 신호는 개발자들의 3분의 1이 버클리의 핵심팀에서 온다는 것과 참여자의 증가이다.
새로운 전개방식
Mesos의 상단에서 동작할 뿐만 아니라 Spark는 독립모드로 배포될 수 있다: 사용자들은 오직 각각의 노드에서 Spark와 JVM을 설치하기만 하면 Spark 0.6과 함께 설치되는 간단한 클러스터매니저(2)가 나머지를 처리한다. Spark의 배포가 더욱 간단해져서 Mesos(와 C++)에 익숙하지 않은 조직에게 그들의 클러스터에 Spark를 동작하게 한다. 이번 버전은 Apache YARN에서 Spark를 실행하기위한 시험모드도 제공한다.
새로운 자바 API
내가 오직 Scala를 통해서만 Spark를 사용하는 동안 많은 자바개발자들은 JAVA API를 요구해왔다. 버전 0.6과함께 기다림은 끝났다: 모든 Spark의 기능들은 API를 통해 자바로부터 정보를 얻어올 수 있다. Python API도 멀지 않았다.
RDD 지속옵션
RDD"s는 메모리에 캐시할 수 있고 컴퓨터 노드들의 클러스터를 가로지를 수 있는 분산된 객체이다. 그것은 Spark에서 사용하는 핵심적인 데이터 객체이다. 버전 0.6의 캐시방법은 개별적인 RDD레벨에서 조정가능하다. 사용자들은 RDD를 메모리에 저장할 것인지 디스크에 저장 할 것인지 연속해서 저장할 것인지 노드들에 복제(3)할 것인지 결정할 수 있다.
상당한 성능향상
Spark의 통신 계층은 개정(4)되었고 특히 대화형 쿼리와 front-end 애플리케이션으로부터의 답변요청에서 대기시간이 줄어들었다. Shuffle은 또한 개정(5)되었고 "groupByKey", "reduceByKey" 그리고 분류와 같은 많은 보통의 RDD 오퍼레이터들을 2배 더 빠르게 동작할 수 있게 하였다.
개발툴과 설명서
버전0.6을 시작하면서 Spark는 쉽게 읽을 수 있는 HTML설명서를 소스트리 안에 첨부할 것이다. 또한 Spark와 Mesos는 현재 두 가지 프로젝트를 링크하기가 더 편해진 것을 Mavan을 통해 발표할 것이다. 또한 개선된 로깅과 디버깅툴은 당신의 코드의 각각의 부분들을 더 쉽게 볼 수 있게 해줄 것이다.
Shark 업데이트(Shark 버전 0.2)
Spark는 많은 공통의 분석타입을 위해 잘 맞는 툴(6)를 제공한다 대화형 쿼리의 분석을 위해 Shark(7)은 HiveQL를 통해서 SQL-like를 제공한다. 데이터의 이너쿼리캐싱 때문에 Shark는 Hive보다 훨씬 더 빠르게 동작하는 경향이 있다.
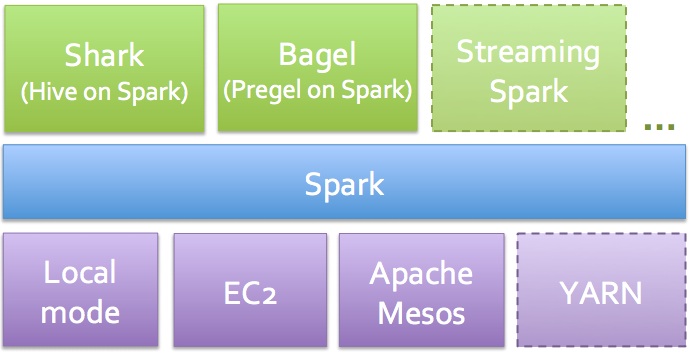
Spark 버전 0.2에서 기본성능의 향상은 조인과 그룹바이에 있다: 요소들의 결합은 성능을 2배까지 끌어올린다. 첫 번째로 Shuffle에서 명시된바와 같이 Spark0.6은 훨씬 빠르다. 또한 개발자들은 그룹바이와 조인에(JVM 가비지콜렉션 시간에 영향을 주는) 의해서 생성된 임시객체들을 줄일 수 있다. 마지막으로 불필요한 데이터의 더블 버퍼링이나 작업이 제거된다.
Shark 0.2버전에서 사용이 가능한 다른 업데이트들
(1) Shark는 Spark0.6의 독립적인 전개모드에서 동작할 것이다.
(2) Hive버전 0.9를 지원한다.
(3) Hive의 ADD FILE명령을 사용(8)하는 UDF와 UDAF의 종속장치를 추가하고 배포할 수있는 능력
(4) Shark Thrift server mode (야후가 제시하고 Hive Thrift server와 호환되는)는 여러 클라이언트가 캐시 테이블의 동일한 집합을 사용하는 데이터 웨어하우스에 접근할 수 있게 해준다.
또한 Shark 버전0.3.은 몇 주내에 배포될 것이다. 버전 0.3.의 업데이트는 컬럼의 요약과 캐시테이블에 대한 범위를 좁혀주고 클러스터에서 Shark의 메모리공간을 찾기 위한 간단한 대쉬보드를 포함하고 있다.
덧붙여서, 조만간 Spark Streaming을 포함하는 또 다른 중요한 버전이 배포될 예정이다(실시간 애플리케이션을 위한).
*****
(0) 많은 Spark의 이용자들은 이미 Spark의 유용성과 성능에 대해 확고한 믿음이 있다. 나는 Spark의 개발팀이 사용자들의 인원을 늘리는데 도움이 되는 기능들을 개발하는데 초점이 맞춰져있다는 사실을 좋아한다.
(1) 이 포스트는 Spark와 Shark의 개발자들의 팀장인 Matei Zaharia와 Reynold Xin의 인터뷰를 기반으로 했다.
(2) 규모를 줄인 클러스터 매니저는 특별히 Spark를 동작시키기위해 빌드했다. 이것은 클러스터의 동작이나 프로세스들을 관찰하기 위한 웹 인터페이스를 포함한다.
(3) RDD의 경우 이전 버전인 0.6으로 불가능했다.
(4) 이것은 Control Plane 최적화를 포함한다.
(5) 네트워크 동작을 포함하는 계산의 속도를 높이기 위해 Shuffle은 HTTP기반에서 비동기식 NIO기반으로 변경되었다.
(6) 당신은 툴의 집합을 섞고 일치시키는 것보다(예를들어 Hive,Hadoop,Mahout, S4/Storm 등) 한가지 프로그래밍 패러다임을 배우는 것이 낫다.
(7) Hive와 Shark의 가장 큰 차이점은 물리적 구조의 생성이다: Shark가 RDD를 바꾸는식으로 변화해왔다면 Hive는 별도의 맵과 일을 줄이는 방식으로 변화해왔다.
(8) 사용자들은 이전에 클래스 패스에 JARs처럼 UDFs를 포함시켜야했다.
저자 : Ben Lorica
역자 : 하혜진
원문 : Spark 0.6 improves performance and accessibility
Spark의 개발팀은 Spark를 쓰는 유저들이 늘어날 수 있는 기능을 제공하는데 노력하고 있다.
저번 포스트에서 왜 내가 Spark를 수용했고 쓰는지 몇 가지 이유를 나열했었다. 나는 특히 Spark가 왜 반복되는 계산이나 상호연관된 쿼리같은 많이 분산된 빅데이터 분석업무에 Hadoop을 능가할만큼 잘 맞는지 설명했었다. 버전 0.6에서 Spark는 더 빨라지고 더 쓰기 쉬워진다(0). 릴리즈노트는 모든 세세한 변경을 포함하지만, 아래 highlights(1)에서 확인할 수 있듯이 버전 0.6은 상당히 중요한 버전이다. 또 다른 좋은 신호는 개발자들의 3분의 1이 버클리의 핵심팀에서 온다는 것과 참여자의 증가이다.
새로운 전개방식
Mesos의 상단에서 동작할 뿐만 아니라 Spark는 독립모드로 배포될 수 있다: 사용자들은 오직 각각의 노드에서 Spark와 JVM을 설치하기만 하면 Spark 0.6과 함께 설치되는 간단한 클러스터매니저(2)가 나머지를 처리한다. Spark의 배포가 더욱 간단해져서 Mesos(와 C++)에 익숙하지 않은 조직에게 그들의 클러스터에 Spark를 동작하게 한다. 이번 버전은 Apache YARN에서 Spark를 실행하기위한 시험모드도 제공한다.
새로운 자바 API
내가 오직 Scala를 통해서만 Spark를 사용하는 동안 많은 자바개발자들은 JAVA API를 요구해왔다. 버전 0.6과함께 기다림은 끝났다: 모든 Spark의 기능들은 API를 통해 자바로부터 정보를 얻어올 수 있다. Python API도 멀지 않았다.
RDD 지속옵션
RDD"s는 메모리에 캐시할 수 있고 컴퓨터 노드들의 클러스터를 가로지를 수 있는 분산된 객체이다. 그것은 Spark에서 사용하는 핵심적인 데이터 객체이다. 버전 0.6의 캐시방법은 개별적인 RDD레벨에서 조정가능하다. 사용자들은 RDD를 메모리에 저장할 것인지 디스크에 저장 할 것인지 연속해서 저장할 것인지 노드들에 복제(3)할 것인지 결정할 수 있다.
상당한 성능향상
Spark의 통신 계층은 개정(4)되었고 특히 대화형 쿼리와 front-end 애플리케이션으로부터의 답변요청에서 대기시간이 줄어들었다. Shuffle은 또한 개정(5)되었고 "groupByKey", "reduceByKey" 그리고 분류와 같은 많은 보통의 RDD 오퍼레이터들을 2배 더 빠르게 동작할 수 있게 하였다.
개발툴과 설명서
버전0.6을 시작하면서 Spark는 쉽게 읽을 수 있는 HTML설명서를 소스트리 안에 첨부할 것이다. 또한 Spark와 Mesos는 현재 두 가지 프로젝트를 링크하기가 더 편해진 것을 Mavan을 통해 발표할 것이다. 또한 개선된 로깅과 디버깅툴은 당신의 코드의 각각의 부분들을 더 쉽게 볼 수 있게 해줄 것이다.
Shark 업데이트(Shark 버전 0.2)
Spark는 많은 공통의 분석타입을 위해 잘 맞는 툴(6)를 제공한다 대화형 쿼리의 분석을 위해 Shark(7)은 HiveQL를 통해서 SQL-like를 제공한다. 데이터의 이너쿼리캐싱 때문에 Shark는 Hive보다 훨씬 더 빠르게 동작하는 경향이 있다.
Spark 버전 0.2에서 기본성능의 향상은 조인과 그룹바이에 있다: 요소들의 결합은 성능을 2배까지 끌어올린다. 첫 번째로 Shuffle에서 명시된바와 같이 Spark0.6은 훨씬 빠르다. 또한 개발자들은 그룹바이와 조인에(JVM 가비지콜렉션 시간에 영향을 주는) 의해서 생성된 임시객체들을 줄일 수 있다. 마지막으로 불필요한 데이터의 더블 버퍼링이나 작업이 제거된다.
Shark 0.2버전에서 사용이 가능한 다른 업데이트들
(1) Shark는 Spark0.6의 독립적인 전개모드에서 동작할 것이다.
(2) Hive버전 0.9를 지원한다.
(3) Hive의 ADD FILE명령을 사용(8)하는 UDF와 UDAF의 종속장치를 추가하고 배포할 수있는 능력
(4) Shark Thrift server mode (야후가 제시하고 Hive Thrift server와 호환되는)는 여러 클라이언트가 캐시 테이블의 동일한 집합을 사용하는 데이터 웨어하우스에 접근할 수 있게 해준다.
또한 Shark 버전0.3.은 몇 주내에 배포될 것이다. 버전 0.3.의 업데이트는 컬럼의 요약과 캐시테이블에 대한 범위를 좁혀주고 클러스터에서 Shark의 메모리공간을 찾기 위한 간단한 대쉬보드를 포함하고 있다.
덧붙여서, 조만간 Spark Streaming을 포함하는 또 다른 중요한 버전이 배포될 예정이다(실시간 애플리케이션을 위한).
*****
(0) 많은 Spark의 이용자들은 이미 Spark의 유용성과 성능에 대해 확고한 믿음이 있다. 나는 Spark의 개발팀이 사용자들의 인원을 늘리는데 도움이 되는 기능들을 개발하는데 초점이 맞춰져있다는 사실을 좋아한다.
(1) 이 포스트는 Spark와 Shark의 개발자들의 팀장인 Matei Zaharia와 Reynold Xin의 인터뷰를 기반으로 했다.
(2) 규모를 줄인 클러스터 매니저는 특별히 Spark를 동작시키기위해 빌드했다. 이것은 클러스터의 동작이나 프로세스들을 관찰하기 위한 웹 인터페이스를 포함한다.
(3) RDD의 경우 이전 버전인 0.6으로 불가능했다.
(4) 이것은 Control Plane 최적화를 포함한다.
(5) 네트워크 동작을 포함하는 계산의 속도를 높이기 위해 Shuffle은 HTTP기반에서 비동기식 NIO기반으로 변경되었다.
(6) 당신은 툴의 집합을 섞고 일치시키는 것보다(예를들어 Hive,Hadoop,Mahout, S4/Storm 등) 한가지 프로그래밍 패러다임을 배우는 것이 낫다.
(7) Hive와 Shark의 가장 큰 차이점은 물리적 구조의 생성이다: Shark가 RDD를 바꾸는식으로 변화해왔다면 Hive는 별도의 맵과 일을 줄이는 방식으로 변화해왔다.
(8) 사용자들은 이전에 클래스 패스에 JARs처럼 UDFs를 포함시켜야했다.
TAG :
이전 글 : 얼굴 추적 램프
다음 글 : 구글 북 스캐너 만들기

최신 콘텐츠