IT/모바일
3.3 인터넷 크롤링
필자가 웹 스크레이핑에 대해 이야기할 때마다 누군가는 항상 이렇게 묻습니다. “구글 같은 기업은 어떻게 만들어지나요?” 필자의 대답은 항상 같습니다. “첫째, 수십억 달러를 모아 세계에서 가장 훌륭한 데이터센터를 만들고 세계 곳곳에 배치합니다. 두 번째로, 웹 크롤러를 만듭니다.”
구글이 1996년에 처음 시작되었을 때는 단 두 명의 스탠퍼드 대학원생뿐이었고, 그들이 가진 건 낡은 서버와 파이썬 웹 크롤러뿐이었습니다. 이제 당신도 이 사실을 알았으니, 다음 IT 억만장자가 될 수단을 갖춘 겁니다!
진지하게 말해서, 웹 크롤러는 여러 가지 최신 웹 기술의 핵심에 있고, 웹 크롤러를 사용하기 위해 반드시 거대한 데이터센터가 필요하지는 않습니다. 도메인 간 데이터 분석을 위해서는 인터넷의 무수히 많은 페이지에서 데이터를 가져오고 해석할 수 있는 크롤러가 필요합니다.
이전 예제와 마찬가지로 지금부터 만들 웹 크롤러도 링크를 따라 페이지와 페이지를 이동합니다. 하지만 이번에는 외부 링크를 무시하지 않고 따라갈 겁니다. 한 가지 도전이 추가됩니다. 이번에는 각 페이지에 관한 정보를 기록할 수 있는지 알아볼 겁니다. 여태까지 했던 것처럼 도메인 하나만 다루는 것보다는 어려울 겁니다. 웹사이트마다 레이아웃이 완전히 다르니까요. 따라서 어떤 정보를 찾을지, 어떻게 찾을지 매우 유연한 사고방식을 가져야 합니다.

CAUTION_ 지금부터 일어날 일은 아무도 모릅니다
다음 섹션에서 사용할 코드는 인터넷 어디든지 갈 수 있음을 염두에 두십시오. 위키백과의 여섯 다리를 이해했다면 http://www.sesamestreet.org/ 에서 단 몇 번의 이동으로도 이상한 사이트에 도달할 수 있다는 것도 이해할 겁니다.
미성년자라면 이 코드를 실행하기 전에 먼저 부모와 상의하십시오. 법 규정이나 종교적인 이유로 성적인 사이트의 텍스트를 읽는 것을 금지한다면, 이후의 코드 예제를 읽는 건 상관없어도 실제 실행할 때는 주의를 기울이십시오.
단순히 외부 링크를 닥치는 대로 따라가는 크롤러를 만들기 전에 먼저 자신에게 다음과 같은 질문을 해보십시오.
- 내가 수집하려 하는 데이터는 어떤 것이지? 정해진 사이트 몇 개만 수집하면 되나? (이런 경우, 거의 틀림 없이 더 쉬운 방법이 있습니다.) 아니면 그런 사이트가 있는지조차 몰랐던 사이트에도 방문하는 크롤러가 필요할까?
- 크롤러가 특정 웹사이트에 도달하면, 즉시 새 웹사이트를 가리키는 링크를 따라가야 할까? 아니면 한동안 현재 웹사이트에 머물면서 파고들어야 할까?
- 특정 사이트를 스크랩에서 제외할 필요는 없나? 비 영어권 콘텐츠도 수집해야 할까?
- 만약 크롤러가 방문한 사이트의 웹마스터가 크롤러의 방문을 알아차렸다면 나 자신을 법적으로 보호할 수 있을까? (이 주제에 관해서는 부록 C를 읽어보십시오.)
파이썬 함수를 결합하면 다양한 웹 스크레이핑을 실행하는 코드를 쉽게 만들 수 있고, 이는 50줄도 안 되는 코드로도 충분히 가능합니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
# 페이지에서 발견된 내부 링크를 모두 목록으로 만듭니다.
def getInternalLinks(bsObj, includeUrl):
internalLinks = []
# /로 시작하는 링크를 모두 찾습니다.
for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
internalLinks.append(link.attrs['href'])
return internalLinks
# 페이지에서 발견된 외부 링크를 모두 목록으로 만듭니다.
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
# 현재 URL을 포함하지 않으면서 http나 www로 시작하는 링크를 모두 찾습니다.
for link in bsObj.findAll("a",
href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def splitAddress(address):
addressParts = address.replace("http://", "").split("/")
return addressParts
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bsObj = BeautifulSoup(html, "html.parser")
externalLinks = getExternalLinks(bsObj, splitAddress(startingPage)[0])
if len(externalLinks) == 0:
internalLinks = getInternalLinks(startingPage)
return getNextExternalLink(internalLinks[random.randint(0,
len(internalLinks)-1)])
else:
return externalLinks[random.randint(0, len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink("http://oreilly.com")
print("Random external link is: "+externalLink)
followExternalOnly(externalLink)
followExternalOnly("http://oreilly.com")
위 프로그램은 http://oreilly.com 에서 시작해 외부 링크에서 외부 링크로 무작위로 이동합니다. 다음은 위 프로그램의 출력 결과 예제입니다.
Random external link is: http://igniteshow.com/
Random external link is: http://feeds.feedburner.com/oreilly/news
Random external link is: http://hire.jobvite.com/CompanyJobs/Careers.aspx?c=q319
Random external link is: http://makerfaire.com/
...
웹사이트의 첫 번째 페이지에 항상 외부 링크가 있다는 보장은 없습니다. 여기서는 외부 링크를 찾기 위해 이전 크롤링 예제와 비슷한 방법, 즉 외부 링크를 찾을 때까지 웹사이트를 재귀적으로 파고드는 방법을 썼습니다.
[그림 3-1]은 이러한 작업 내용을 시각화한 순서도입니다.
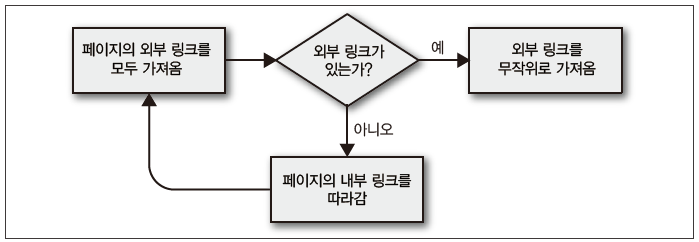
그림 3-1 인터넷 사이트를 탐색하는 스크립트 순서도
CAUTION_ 예제 프로그램을 실무에 쓰지 마십시오
공백과 가독성 때문에, 이 책에 있는 예제 프로그램에는 실무 코드라면 당연히 있어야 할 점검 내용과 예외 처리가 항상 들어 있지는 않습니다.
예를 들어 이 크롤러가 방문한 사이트에 외부 링크가 하나도 없다면(흔치 않지만, 크롤러를 오래 실행한다면 언젠가 반드시 일어납니다), 이 프로그램은 파이썬의 재귀 제한에 걸릴 때까지 계속 실행됩니다.
이 코드를 중요한 목적에 쓰기 전에 잠재적 함정을 처리할 수 있는 코드를 잊지 말고 넣으십시오.
작업을 ‘이 페이지에 있는 모든 외부 링크를 찾는다’ 같은 단순한 함수로 나누면, 나중에 코드를 다른 크롤링 작업에 쓸 수 있도록 리팩토링하기 쉽습니다. 예를 들어 사이트 전체에서 외부 링크를 검색하고 각 링크마다 메모를 남기고 싶다면 다음과 같은 함수를 추가하면 됩니다.(역자주_ 이 예제 코드 및 원서 깃허브에 있는 코드는 상대 경로를 제대로 처리하지 못해 http://oreilly.com 사이트에서 작동하지 않습니다. 이에 상대 경로를 처리할 수 있게 소스 코드 일부를 수정했습니다.)
# 사이트에서 찾은 외부 URL을 모두 리스트로 수집
allExtLinks = set()
allIntLinks = set()
def getAllExternalLinks(siteUrl):
html = urlopen(siteUrl)
bsObj = BeautifulSoup(html, "html.parser")
internalLinks = getInternalLinks(bsObj,splitAddress(domain)[0])
externalLinks = getExternalLinks(bsObj,splitAddress(domain)[0])
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.add(link)
print(link)
for link in internalLinks:
if link == "/":
link = domain
elif link[0:2] == "//":
link = "http:" + link
elif link[0:1] == "/":
link = domain + link
if link not in allIntLinks:
print("About to get link: "+link)
allIntLinks.add(link)
getAllExternalLinks(link)
domain = "http://oreilly.com"
getAllExternalLinks(domain)
이 코드는 크게 루프 두 개로 생각할 수 있습니다. 하나는 내부 링크를 수집하고, 다른 하나는 외부 링크를 수집하면서 서로 연관되게 동작합니다. 순서도로 나타낸다면 [그림 3-2]와 비슷할 것입니다.
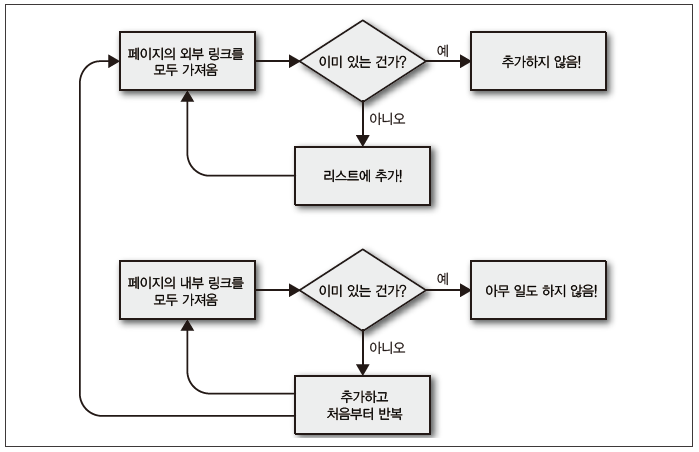
그림 3-2 웹사이트의 외부 링크를 모두 수집하는 크롤러의 순서도
실제 코드를 작성하기 전에 그 코드가 무슨 일을 하는지 다이어그램을 그려보거나 메모해보는 습관을 들이는 게 좋습니다. 크롤러가 복잡해지면 이런 습관이 시간을 매우 많이 절약해주고, 좌절하는 일도 훨씬 줄어들 겁니다.
리다이렉트 처리
리다이렉트를 사용하면 같은 웹 페이지를 다른 도메인 이름 아래에서 볼 수 있습니다. 리다이렉트는 크게 두 가지입니다.
- 서버 쪽 리다이렉트. 페이지를 불러오기 전에 URL이 바뀝니다.
- 클라이언트 쪽 리다이렉트. 이따금 페이지를 리다이렉트하기 전에 ‘You will be directed in 10 seconds...’ 같은 메시지가 나올 때도 있습니다.
이 섹션에서는 서버 쪽 리다이렉트를 다룹니다. 자바스크립트나 HTML을 사용하는 클라이언트 쪽 리다이렉트에 대해서는 10장을 보십시오.
서버 쪽 리다이렉트에 대해서는 보통 별로 신경 쓸 일이 없습니다. 파이썬 3.x에서 제공하는 urllib 라이브러리가 리다이렉트를 자동으로 처리해주니까요. 그저 이따금 크롤링하는 페이지 URL이 입력한 URL과 정확히 일치하지 않을 수 있다는 것만 기억하면 됩니다.
이전 글 : Pynini로 파이썬에서 텍스트 처리하기
다음 글 : 애자일 방법들
관련 콘텐츠
![[파이썬으로 웹 크롤러 만들기] 고급 HTML 분석(4/4)](/data/cms/CMS2068924870_thumb.jpg)
![[파이썬으로 웹 크롤러 만들기] 고급 HTML 분석(3/4)](/data/cms/CMS2014562269_thumb.jpg)
![[파이썬으로 웹 크롤러 만들기] 고급 HTML 분석(2/4)](/data/cms/CMS6168044195_thumb.jpg)
![[파이썬으로 웹 크롤러 만들기] 고급 HTML 분석(1/4)](/data/cms/CMS5482220797_thumb.jpg)
![[파이썬으로 웹 크롤러 만들기] 크롤링 시작하기(2/3)](/data/cms/CMS8089664518_thumb.jpg)
![[파이썬으로 웹 크롤러 만들기] 크롤링 시작하기(1/3)](/data/cms/CMS1068441311_thumb.jpg)

최신 콘텐츠